seaborn.boxenplot#
- seaborn.boxenplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, dodge='auto', width=0.8, gap=0, linewidth=None, linecolor=None, width_method='exponential', k_depth='tukey', outlier_prop=0.007, trust_alpha=0.05, showfliers=True, hue_norm=None, log_scale=None, native_scale=False, formatter=None, legend='auto', scale=<deprecated>, box_kws=None, flier_kws=None, line_kws=None, ax=None, **kwargs)#
Draw an enhanced box plot for larger datasets.
This style of plot was originally named a “letter value” plot because it shows a large number of quantiles that are defined as “letter values”. It is similar to a box plot in plotting a nonparametric representation of a distribution in which all features correspond to actual observations. By plotting more quantiles, it provides more information about the shape of the distribution, particularly in the tails.
See the tutorial for more information.
Note
By default, this function treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis. As of version 0.13.0, this can be disabled by setting
native_scale=True.- Parameters:
- dataDataFrame, Series, dict, array, or list of arrays
Dataset for plotting. If
xandyare absent, this is interpreted as wide-form. Otherwise it is expected to be long-form.- x, y, huenames of variables in
dataor vector data Inputs for plotting long-form data. See examples for interpretation.
- order, hue_orderlists of strings
Order to plot the categorical levels in; otherwise the levels are inferred from the data objects.
- orient“v” | “h” | “x” | “y”
Orientation of the plot (vertical or horizontal). This is usually inferred based on the type of the input variables, but it can be used to resolve ambiguity when both
xandyare numeric or when plotting wide-form data.Changed in version v0.13.0: Added ‘x’/’y’ as options, equivalent to ‘v’/’h’.
- colormatplotlib color
Single color for the elements in the plot.
- palettepalette name, list, or dict
Colors to use for the different levels of the
huevariable. Should be something that can be interpreted bycolor_palette(), or a dictionary mapping hue levels to matplotlib colors.- saturationfloat
Proportion of the original saturation to draw fill colors in. Large patches often look better with desaturated colors, but set this to
1if you want the colors to perfectly match the input values.- fillbool
If True, use a solid patch. Otherwise, draw as line art.
New in version v0.13.0.
- dodge“auto” or bool
When hue mapping is used, whether elements should be narrowed and shifted along the orient axis to eliminate overlap. If
"auto", set toTruewhen the orient variable is crossed with the categorical variable orFalseotherwise.Changed in version 0.13.0: Added
"auto"mode as a new default.- widthfloat
Width allotted to each element on the orient axis. When
native_scale=True, it is relative to the minimum distance between two values in the native scale.- gapfloat
Shrink on the orient axis by this factor to add a gap between dodged elements.
New in version 0.13.0.
- linewidthfloat
Width of the lines that frame the plot elements.
- linecolorcolor
Color to use for line elements, when
fillis True.New in version v0.13.0.
- width_method{“exponential”, “linear”, “area”}
Method to use for the width of the letter value boxes:
"exponential": Represent the corresponding percentile"linear": Decrease by a constant amount for each box"area": Represent the density of data points in that box
- k_depth{“tukey”, “proportion”, “trustworthy”, “full”} or int
The number of levels to compute and draw in each tail:
"tukey": Use log2(n) - 3 levels, covering similar range as boxplot whiskers"proportion": Leave approximatelyoutlier_propfliers"trusthworthy": Extend to level with confidence of at leasttrust_alpha"full": Use log2(n) + 1 levels and extend to most extreme points
- outlier_propfloat
Proportion of data expected to be outliers; used when
k_depth="proportion".- trust_alphafloat
Confidence threshold for most extreme level; used when
k_depth="trustworthy".- showfliersbool
If False, suppress the plotting of outliers.
- hue_normtuple or
matplotlib.colors.Normalizeobject Normalization in data units for colormap applied to the
huevariable when it is numeric. Not relevant ifhueis categorical.New in version v0.12.0.
- log_scalebool or number, or pair of bools or numbers
Set axis scale(s) to log. A single value sets the data axis for any numeric axes in the plot. A pair of values sets each axis independently. Numeric values are interpreted as the desired base (default 10). When
NoneorFalse, seaborn defers to the existing Axes scale.New in version v0.13.0.
- native_scalebool
When True, numeric or datetime values on the categorical axis will maintain their original scaling rather than being converted to fixed indices.
New in version v0.13.0.
- formattercallable
Function for converting categorical data into strings. Affects both grouping and tick labels.
New in version v0.13.0.
- legend“auto”, “brief”, “full”, or False
How to draw the legend. If “brief”, numeric
hueandsizevariables will be represented with a sample of evenly spaced values. If “full”, every group will get an entry in the legend. If “auto”, choose between brief or full representation based on number of levels. IfFalse, no legend data is added and no legend is drawn.New in version v0.13.0.
- box_kws: dict
Keyword arguments for the box artists; passed to
matplotlib.patches.Rectangle.New in version v0.12.0.
- line_kws: dict
Keyword arguments for the line denoting the median; passed to
matplotlib.axes.Axes.plot().New in version v0.12.0.
- flier_kws: dict
Keyword arguments for the scatter denoting the outlier observations; passed to
matplotlib.axes.Axes.scatter().New in version v0.12.0.
- axmatplotlib Axes
Axes object to draw the plot onto, otherwise uses the current Axes.
- kwargskey, value mappings
Other keyword arguments are passed to
matplotlib.patches.Rectangle, superceded by those inbox_kws.
- Returns:
- axmatplotlib Axes
Returns the Axes object with the plot drawn onto it.
See also
violinplotA combination of boxplot and kernel density estimation.
boxplotA traditional box-and-whisker plot with a similar API.
catplotCombine a categorical plot with a
FacetGrid.
Notes
For a more extensive explanation, you can read the paper that introduced the plot: https://vita.had.co.nz/papers/letter-value-plot.html
Examples
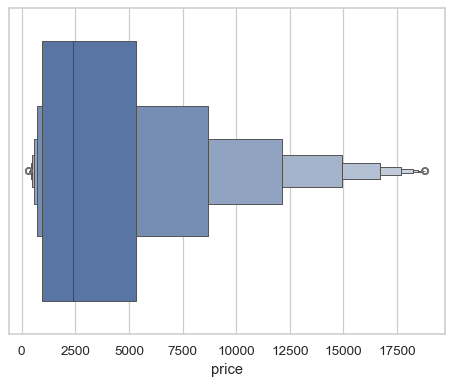
Draw a single horizontal plot, assigning the data directly to the coordinate variable:
sns.boxenplot(x=diamonds["price"])
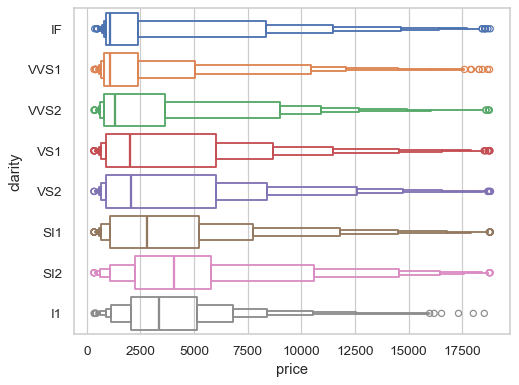
Group by a categorical variable, referencing columns in a datafame
sns.boxenplot(data=diamonds, x="price", y="clarity")
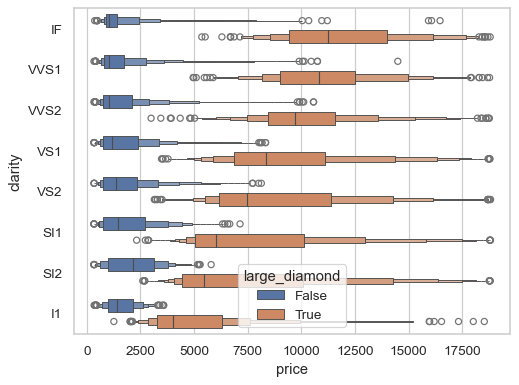
Group by another variable, representing it by the color of the boxes. By default, each boxen plot will be “dodged” so that they don’t overlap; you can also add a small gap between them:
large_diamond = diamonds["carat"].gt(1).rename("large_diamond") sns.boxenplot(data=diamonds, x="price", y="clarity", hue=large_diamond, gap=.2)
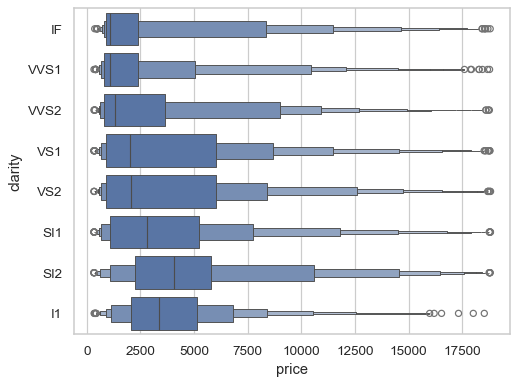
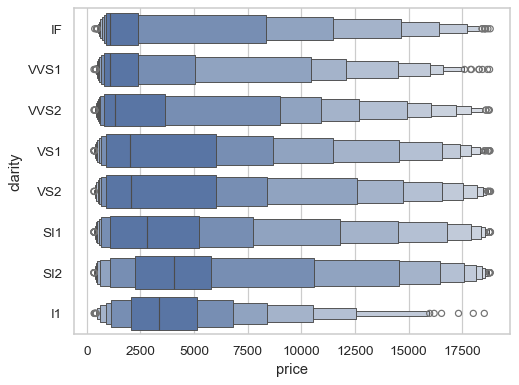
The default rule for choosing each box width represents the percentile covered by the box. Alternatively, you can reduce each box width by a linear factor:
sns.boxenplot(data=diamonds, x="price", y="clarity", width_method="linear")
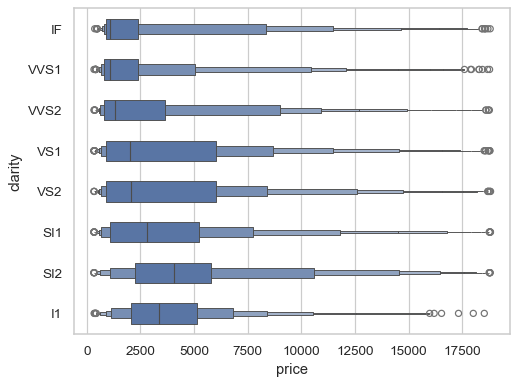
The
widthparameter itself, on the other hand, determines the width of the largest box:sns.boxenplot(data=diamonds, x="price", y="clarity", width=.5)
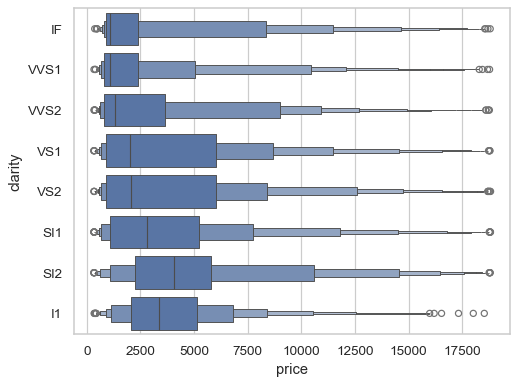
There are several different approaches for choosing the number of boxes to draw, including a rule based on the confidence level of the percentie estimate:
sns.boxenplot(data=diamonds, x="price", y="clarity", k_depth="trustworthy", trust_alpha=0.01)
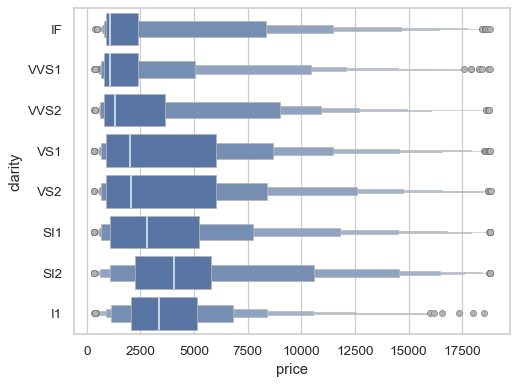
The
linecolorandlinewidthparameters control the outlines of the boxes, while theline_kwsparameter controls the line representing the median and theflier_kwsparameter controls the appearance of the outliers:sns.boxenplot( data=diamonds, x="price", y="clarity", linewidth=.5, linecolor=".7", line_kws=dict(linewidth=1.5, color="#cde"), flier_kws=dict(facecolor=".7", linewidth=.5), )
It is also possible to draw unfilled boxes. With unfilled boxes, all elements will be drawn as line art and follow
hue, when used:sns.boxenplot(data=diamonds, x="price", y="clarity", hue="clarity", fill=False)